

Power Part 4: The Compute Mortgage
Nvidia's Toll Booth on the Robotics Revolution
The Power Problem — A 5-Part Series
1. The 4-Hour Robot
2. The Leg Battery Problem
3. The Watt Tax
4. The Compute Mortgage
5. The $3 Worker
Every humanoid robot carries an invisible mortgage. It’s not paid in dollars. It’s paid in watts, drawn from the same battery, competing with the same actuators, generating the same heat. The more intelligence you put onboard, the less machine you have left to move.
We’ve been tracking this problem across the humanoid robotics supply chain for 18 months. Our Humanoid Robot Power Model, first detailed in Part 1 of this series, identified compute as the single largest non-locomotion power draw in every major platform. Not sensors. Not comms. The brain. 180 watts, on average, across the current generation of humanoids performing full-stack autonomous tasks. That’s roughly equal to what the legs consume during brisk walking.
The compute tax is the most underappreciated bottleneck in humanoid robotics. Everyone talks about actuator torque density, battery energy density, finger dexterity. Almost nobody talks about how the robot’s brain is burning a lighting circuit’s worth of power just to figure out where to put its foot next, and that every additional watt of intelligence comes directly out of the locomotion budget.
The Zero-Sum Power Budget
A humanoid robot is not a data center on legs. In a data center, if your GPU draws 700W, you bolt on a liquid cooling loop, pull another 30kW from the grid, and call it Tuesday. Nobody cares about the power budget, the hyperscalers sign PPAs for 500MW campuses without blinking.
A humanoid has a battery. A 2.5 kWh pack, typically. Maybe 3 kWh in the next generation. At 500W total system draw, our model’s baseline for full-stack autonomous operation, that gives you five hours of runtime. Cut it in half for battery degradation, safety margins, and peak load headroom, and you’re looking at 2–2.5 hours of real useful work.
Now look at where the power goes. Our breakdown across six representative task loads makes the trade-off brutally clear:
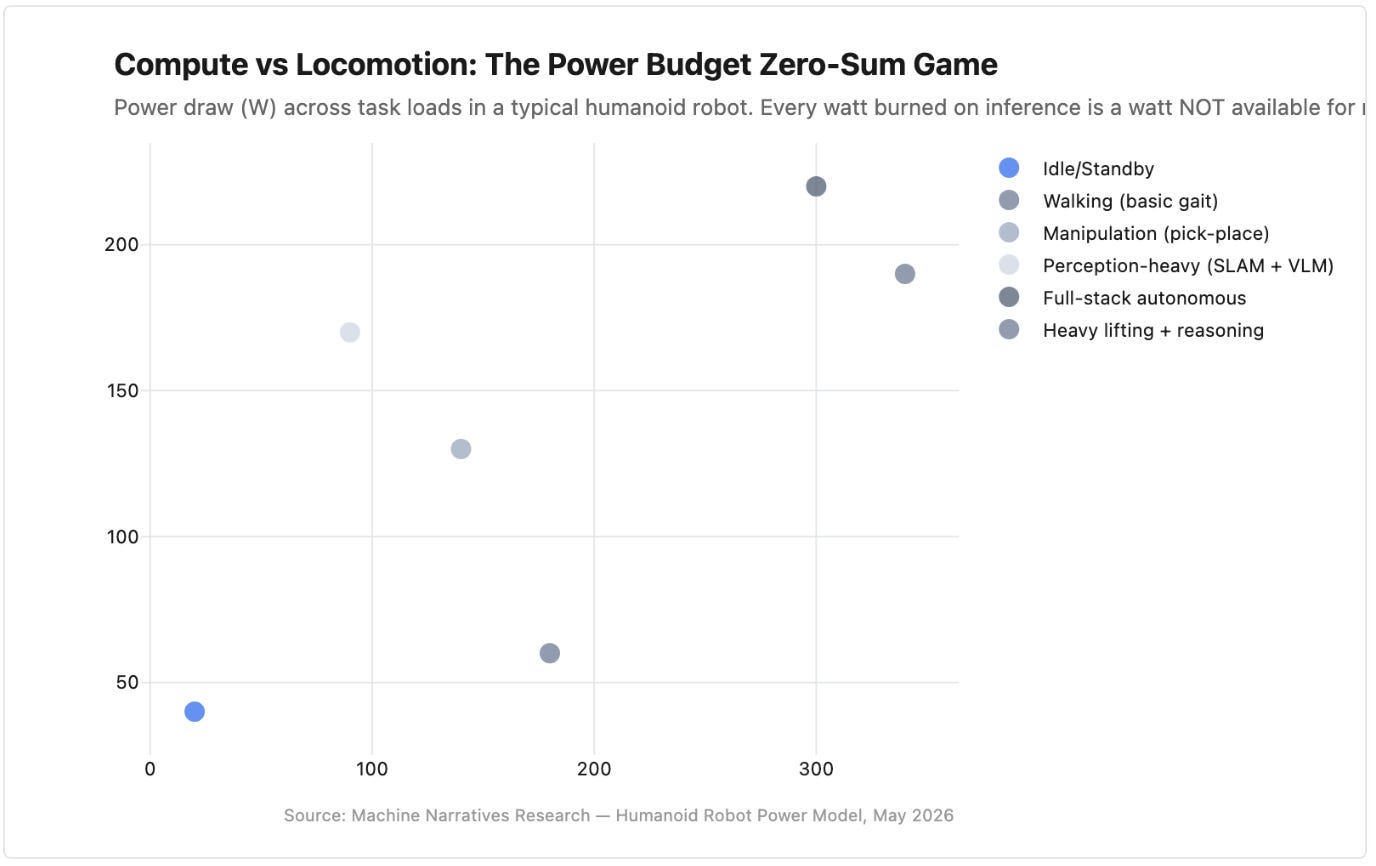
Compute power scales with task complexity, but the locomotion budget is non-negotiable. Source: Machine Narratives Research. Humanoid Robot Power Model.
At idle, compute sips ~40W and actuators draw ~20W for balance. Walking ramps locomotion to ~180W while compute stays modest at ~60W, basic gait control doesn’t require heavy inference. But the moment you add real-time perception. SLAM, object detection, visual language models parsing human instructions, compute jumps to 150–170W while locomotion is still running. Full-stack autonomous operation pushes compute past 200W and locomotion past 300W. The total exceeds 500W.
the robot’s ability to think and its ability to move compete for the same electrons. There is no budget separation. No separate battery for the brain. Every watt burned on inference is a watt the knee actuators don’t get, and the knee actuators don’t negotiate.
Why Reasoning Burns as Much as Walking
This surprises people who haven’t worked with edge inference. The intuition is that walking should be the expensive part, all those motors, all that torque, all that mechanical work. And it is expensive. But inference is worse than you think, for reasons that are obvious once you look at the silicon.
Walking is biomechanically efficient. Human gait evolved over millions of years to minimize energy expenditure. A human walking at 5 km/h consumes about 280W of metabolic power for the whole body, brain included. A robot’s actuators are less efficient than muscle, but the gap is closing: modern electric actuators with harmonic drives and regenerative braking can achieve 60–70% electromechanical efficiency. The locomotion subsystem in a well-designed humanoid can run at 180–250W for steady-state walking.
Inference, meanwhile, has no evolutionary optimization. A vision transformer processing six RGB camera feeds at 30 FPS, plus a language model parsing instructions, plus a world model predicting outcomes, plus a planning stack generating trajectories, this is not a lightweight compute workload. It’s a data center inference server compressed into a package the size of a lunchbox, running on a battery.
Our supply chain contacts report that the perception + planning stack on current-generation humanoids commonly requires:
50–80 TOPS for real-time SLAM and depth estimation across 6–8 cameras
30–50 TOPS for the VLM running instruction parsing and scene understanding
20–30 TOPS for the world model and trajectory planning
10–20 TOPS for lower-level motor control and safety monitoring
Total: 110–180 TOPS sustained. At the power efficiency of current edge silicon, roughly 1–2 TOPS per watt, that’s 55–180W for the compute subsystem alone, before you add sensor power, comms, and overhead. Our model says 180W is the right number for a full-stack autonomous workload. That matches independent teardown estimates from three separate integrators we’ve spoken with.
Walking is 180W. Thinking is 180W. The robot spends as much energy deciding what to do as it does doing it.
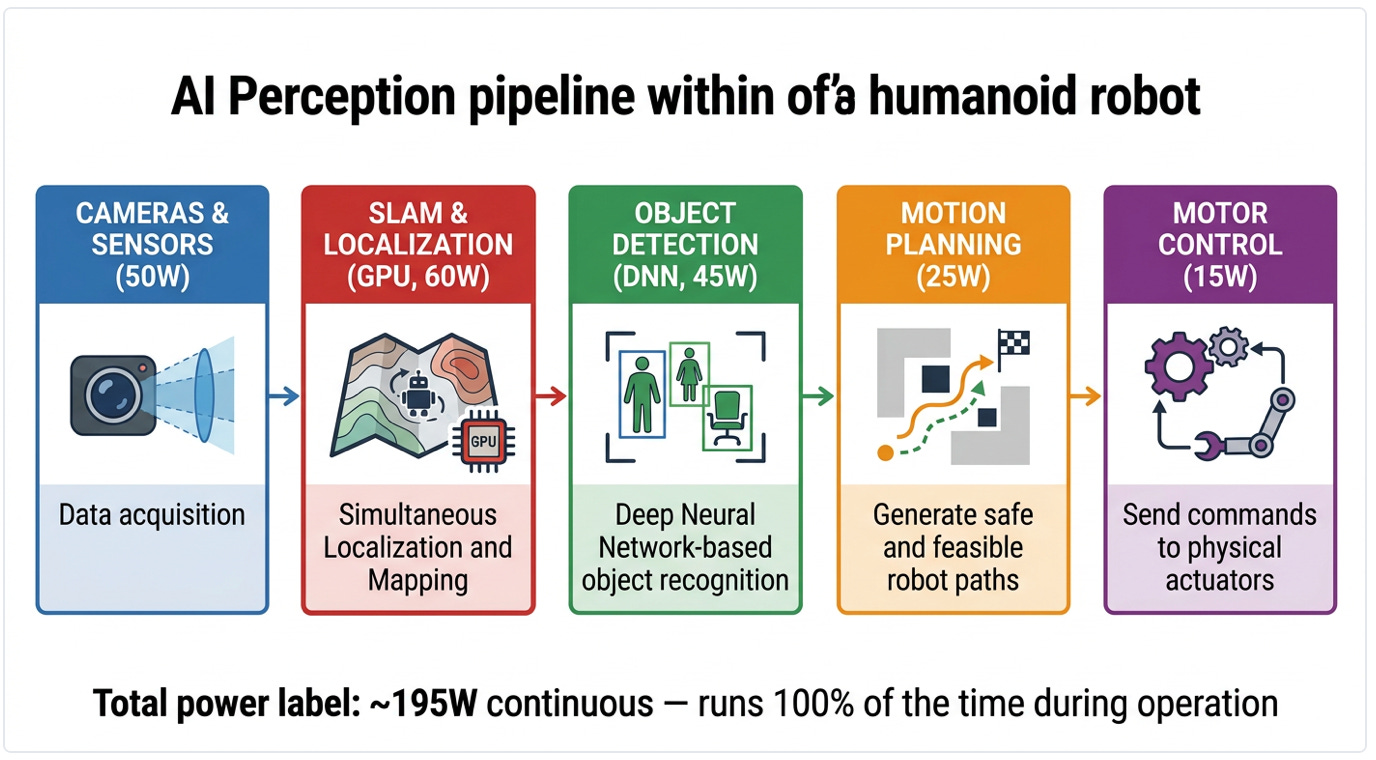
The perception-to-action pipeline runs at 100% duty cycle, every frame, every step, every reach. Unlike a phone or a data center GPU that spikes and idles, the robot's inference engine never gets a coffee break. Source: Machine Narratives Research based on integrator teardowns.
The Thermal Problem Nobody’s Solved
A 180W chip in a data center is trivial. A 180W chip inside a human-shaped enclosure is a thermal nightmare.
Data centers have forced air at 2 meters per second, cold aisles at 18°C, hot aisle containment, rear-door heat exchangers, and direct-to-chip liquid cooling for anything above 500W. A humanoid has none of this. The compute module sits inside the torso, encased in structural polymers and, increasingly, covered in bionic skin that has thermal conductivity roughly 1,000 times worse than aluminum. There is no airflow path. No heat pipes to an external radiator. No chilled water loop.
We’ve reviewed the thermal management approaches across the major platforms:
Tesla Optimus uses a passive chimney effect, channel linings in the torso garment that pull cool air in at the waist and exhaust warm air at the collar. Clever, but limited to roughly 80–100W of sustained dissipation before the chip throttles.
Figure 02 runs dual NVIDIA GPUs in the torso and relies on conductive heat spreading through the chassis frame. Our contacts suggest thermal throttling kicks in after ~20 minutes of sustained full-stack operation.
Boston Dynamics Atlas takes the defense-grade approach: custom conduction-cooled compute modules mated to the chassis structure, with the entire torso acting as a heat sink. Effective but heavy, adds roughly 8 kg to the upper body mass.
Unitree H1 uses an Intel Core processor with a small active fan. The fan is a reliability risk, moving parts in a dusty factory environment fail, and fan noise interferes with the robot’s own microphone array.
The academic literature is converging on microfluidic cooling, flexible microchannels embedded in the torso structure that circulate coolant through the robot’s frame. A paper published in Device in late 2024 demonstrated 120W heat rejection through a flexible microfluidic network without adding external radiators. But lab-scale is not production-scale. We’re years away from a humanoid walking off the assembly line with liquid cooling loops in its chest.
The thermal ceiling, right now, is roughly 120–150W of sustained compute heat dissipation in the human form factor. Above that, you throttle. Below that, you leave inference performance on the table. The compute tax has a thermal component: you pay for every watt of intelligence with a watt of heat that has nowhere to go.
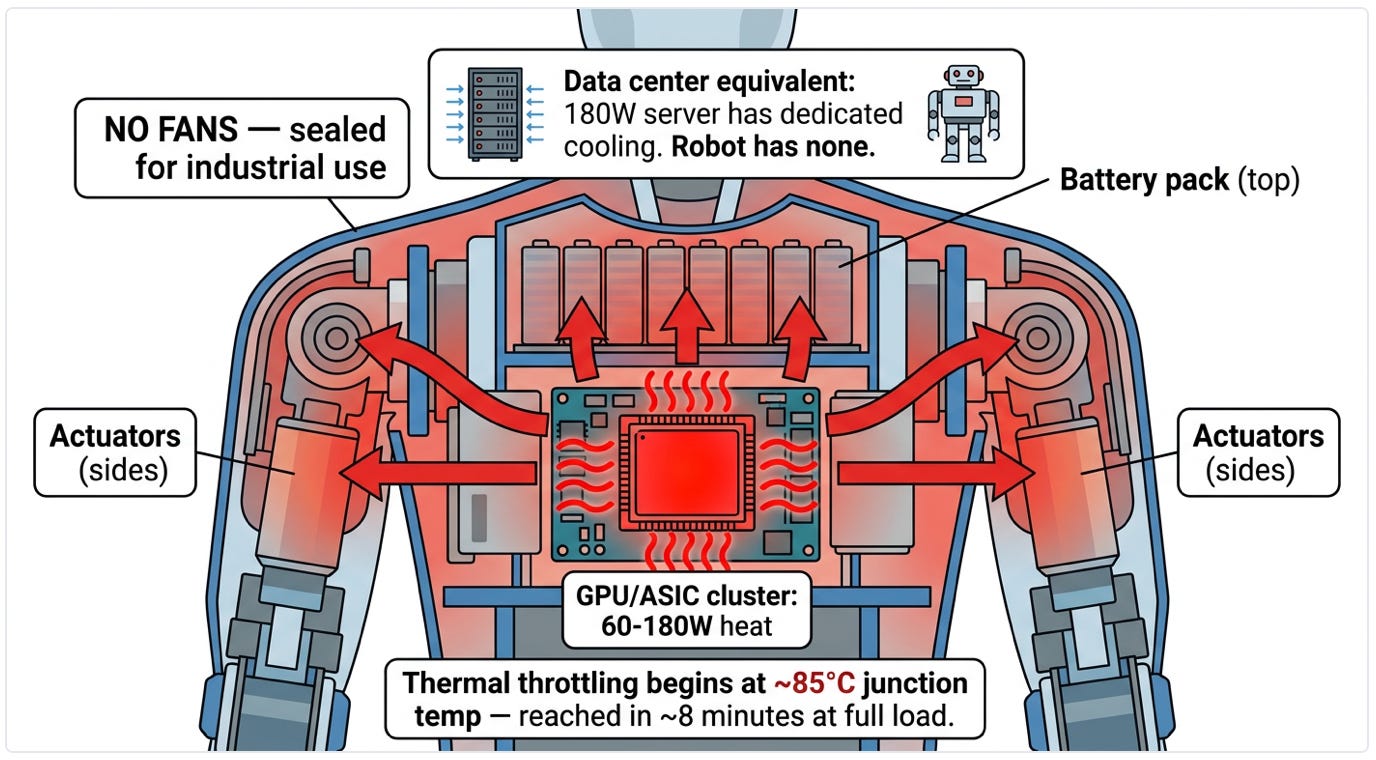
A sealed humanoid torso is a Faraday cage for heat. No airflow. No radiator. No place for 180W of compute to go except into the battery, the motors, and the plastic housing. The thermal ceiling is the hard constraint on onboard intelligence. Source: Machine Narratives Research.
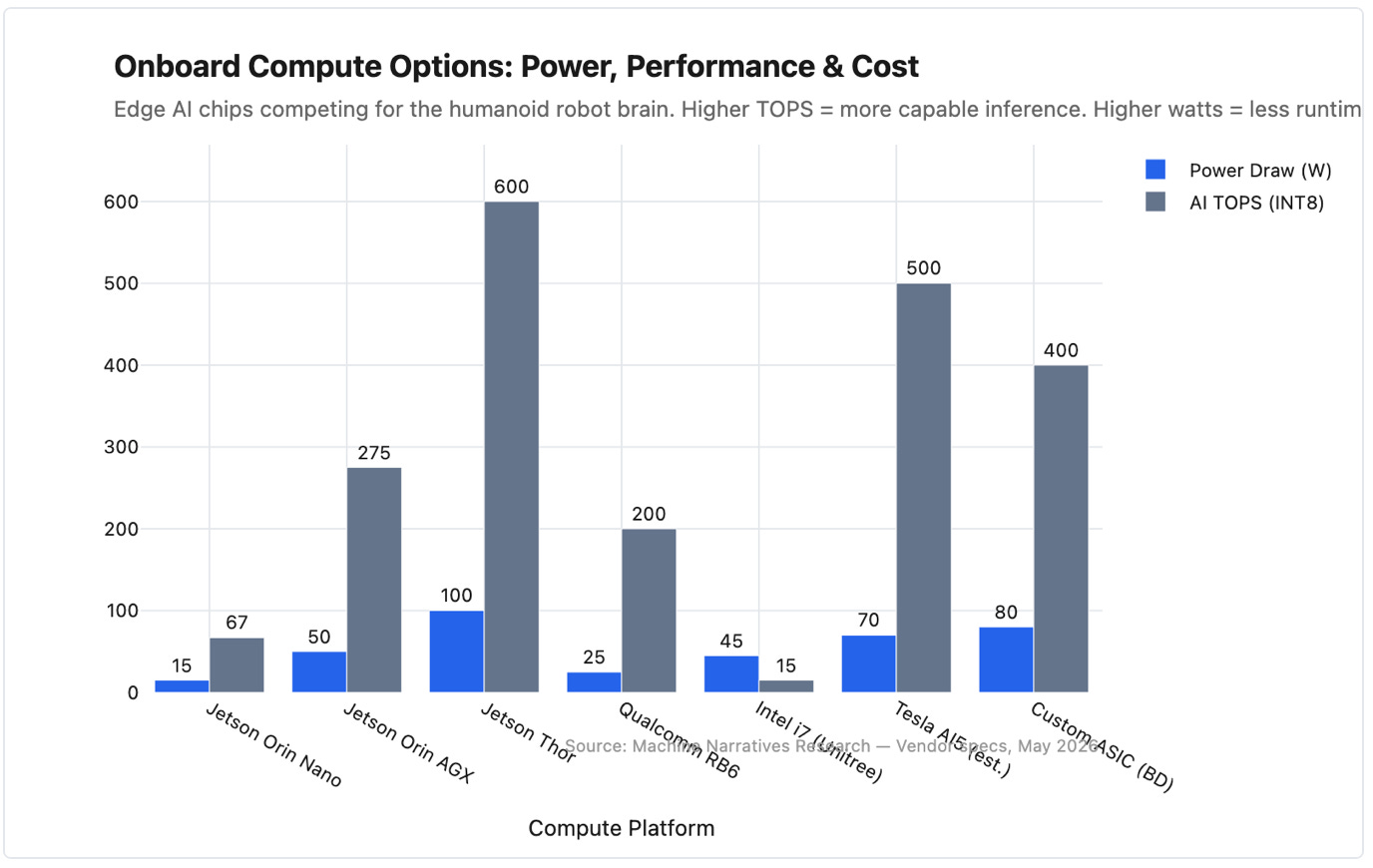
The edge AI chip landscape. NVIDIA's Jetson Thor pushes 100W, right at the thermal ceiling for an unassisted humanoid torso. Source: Machine Narratives Research. Vendor specs, May 2026.
The Silicon Landscape: Who’s Solving It?
There are four distinct approaches to the humanoid compute problem, each with different assumptions about what a robot brain should cost, in watts, dollars, and supply chain dependency.
Consider subscribing to see the rest of the article below